相关背景
模糊测试是非常受欢迎的软件故障发现技术。基于覆盖率的模糊测试工具遇到的关键挑战是如何遍历程序的状态。一些模糊测试工具使用符号执行来解析路径约束,但是符号执行很慢且不能有效地解决多种约束。为了避免模糊测试额外计算量过高的问题,著名的 AFL 放弃了符号执行和任何其它重量级的程序分析技术。它触发程序以观察哪种输入可以发现新的分支状态,并保持这些输入作为之后输入变异的种子。AFL 在模糊测试程序时的额外消耗很低,但大多数变异出的输入都是无效输入(当不断变异却不能触发新状态的时候),因为 AFL 仅仅是盲目的随机变异输入而并没有利用程序的数据流信息。一类模糊测试工具优化 AFL 的方案是使用启发式算法来解决简单的预测问题,如“magic bytes”,但他们不能解决其它类型的路径约束。
主流基线:AFL
AFL 是目前广受欢迎的基于输入变异的灰盒模糊测试工具。AFL 在编译阶段进行轻量级插桩,在变异时使用遗传算法自动发现更可能触发新内部状态的测试用例。作为基于覆盖率的模糊测试器,AFL 通过遍历不同的程序路径触发程序错误。
分支覆盖率
AFL 路径由一系列分支定义。在每次运行过程中,AFL 对每个分支执行了多少次计数。$(I_{prev},I_{cur})$代表一个分支,$I_{prev}$代表分支执行前的基本块ID,$I_{cur}$代表分支语句执行后的基本块ID。AFL 通过轻量级的插桩获取路径信息,其插桩方式为编译时在每个分支点前后注入。每次运行,AFL 分配一个路径跟踪表来对每个分支执行的次数计数,跟踪表的索引是 $hash(I_{prev}, I_{cur})$。
AFL 也在每次运行记录外,保持全局分支覆盖表,每项包含一个 8 位的响亮,记录这个分支在每次运行中执行的次数。b 向量表征一个范围,$b_0 … b_7$ 分别对应着[1],[2],[3],[4,7],[8,15],[16,31],[32,127],[128,$\Inf$]。例如,$b_3$ 被置位,代表该分支被执行了 4 到 7 次。
AFL 通过比较路径追踪表和分支覆盖表,来确定新的输入是否触发了新的内部状态。其两个判定条件是:
- 程序执行了新分支,即路径追踪表有一个表项,而分支覆盖表中没有
- 存在一个分支,执行的次数和任何之前的执行轮次都不同,通过比较 b 向量来判定。
变异策略
- bit / byte 翻转
- 尝试设置焦点 bytes, words 或 dwords
- 对 bytes,words 或 dwords 加或减一个小整数
- 完全随机的单字节集
- 通过覆盖、插入或块 memset,进行块删除,块复制
- 在随机位置结合两个分别的输入文件
解决的问题
- 不考虑调用上下文的情况下,对程序状态的遍历不充分
- 模糊测试过程中,路径约束解析问题
解决方法
Angora 跟踪未触达的分支并尝试解决这些分支的路径约束,提出了四种有效的方式:
- 上下文敏感的分支覆盖:AFL 使用上下文不敏感的分支覆盖来近似程序状态。而在分支覆盖率中添加上下文,允许 Angora 触达更多的程序状态。
- 可扩展的字节级污点分析:大多数路径约束取决于仅仅特定的几个字节,通过跟踪哪些字节会被路径约束检查,使得输入变异的范围可以约束在这些字节,压缩需要探索的状态空间。
- 基于梯度下降的搜索:简单随机效率低下,符号执行计算负担过重且不能有很多约束不能有效解出,启发式算法之外,近年来机器学习中常用提督下降法作为参数优化器,Angora 将梯度下降法迁移到搜索输入变异空间。
- 类型推断:输入中的一组字节,在程序中会被视为一个值,如4个字节被视为 32bit 有符号整数。为了提高梯度下降的效率,Angora 定位这些字节组并推断其类型。
- 输入长度探索:特定程序状态也许在输入超过某些阈值时才能触发,但不论是程序执行还是梯度下降都不能告诉模糊测试器是否需要增加输入长度。Angora 检测到输入长度会影响路径约束,则将输入长度充分延长。
上下文敏感的分支计数
AFL 方式的优势:
- 空间复杂度较低,分支的数量与程序规模呈线性关系
- 使用范围来计算分支执行次数,有助于启发式算法确定是否进入了新的内部状态,随着分支执行次数的增加,需要更显著的变化才能确认进入了新的状态
AFL 方式的限制:
- 上下文无关,无法区分在不同上下文的同一分支的执行
Angora 方式:
- 分支定义为 $(I_{prev},I_{cur},context)$,三项分别为分支前后基本块的 ID,和调用栈的哈希值
- 获得更多种不同的分支情况,但当递归较深时,这种表示就会失效,对此,我们现在的缓解方式是选择一个特定的哈希函数计算调用栈的哈希,对每个函数在初始时分配随机的 ID 并通过异或计算函数调用栈的哈希值,保证了对多次递归调用情况,仅产生至多两个特殊的上下文哈希值
字节级的污点跟踪
为了触达没有触达的分支,定位输入中哪些字节与分支约束有关。然而,污点跟踪非常昂贵,尤其是要对每个字节进行跟踪,因此 AFL 不使用这项技术。
Angora 团队发现,污点跟踪并不是每次运行都是必要的,可以一次运行记录下来不同的字节对应的分支语句。在之后对这些字节变异的过程中,都不在需要重复运行污点跟踪。这使得从摊还分析的角度,昂贵的污点跟踪由多次的信息利用平摊到了一个可以接受的程度。
Angora 为每个程序中变量 x 建立 1 个对应的污点标签 $t_x$ 来表111111111111征 x 在输入中的偏置值。对于污点标签表,要支持以下操作:
- 插入(b):插入一个位向量 b 并返回它的标签
- 查找(t):返回一个与污点标签 t 对应的位向量
- 并集($t_x, t_y$):返回代表$t_x$的位向量和$t_y$到位向量的污点标签
存储污点标签位向量的新数据结构:
- 对每个位向量,数据结构分配一个无符号整数作为专有标签
- 当插入一个位向量时,数据结构分配下一个可用的无符号整数作为它的标签
- 数据结构由映射位向量和标签的二叉树和映射标签到位向量的查找表组成
- 每个位向量 b 对应二叉树中 |b| 层的一个节点 $v_b$,其中 |b|是位向量 b 的长度。$v_b$ 存储了 b 的标签。
- 查找表映射了标签和相应的位向量。一个标签是一个查找表索引,表项内容是指向树节点 $v_b$ 的指针
基于梯度下降的搜索算法
将分支约束视为一个黑盒函数 f(x),x 是输入向量,有以下三种约束:
- f(x) < 0
- f(x) <= 0
- f(x) == 0
随机初始化得到 $x_0$,并以梯度下降法迭代,至 x 的值满足条件。为了解决黑盒约束函数没有解析形式,且可能不连续的问题,使用数值近似,即用一个施加小量计算函数值与原 x 对应函数值的差,与该小量相除得到近似梯度。这个小变化量分别施加在向量的不同维,则得到向量的梯度向量。
类型推断
考虑输入序列,最朴素的方式是把每个字节视为一个序列单元,但是梯度下降法操作的输入向量,如果每个维度对应的类型不匹配会无法计算梯度.为了避免这一问题,需要确定哪几字节为一组,和这个字节组是什么类型的。
通过污点跟踪,当一个指令读取的输入字节序列恰好匹配基本类型的尺寸(1,2,4,8)时,Angora 标记这些字节是属于一个值的。当标注冲突时,Angora 使用最小的分组。Angora 依赖指令语义进行类型推断,即操作该数据指令的操作数类型。
输入长度探索
Angora 在开始模糊测试时的输入长度,与其它模糊测试工具一样,尽可能小。然而,一些分支仅当输入超过阈值时才能出发,这就造成模糊测试工具设计时的一个困境,如果输入太短,就不能触及那些分支,如果输入太长,则会造成运行得很慢甚至可能造成内存不足。与传统的经验值尝试不同,Angora 仅在可能出发新分支的情况下增加输入长度。
在污点分析期间,Angorra 将读取函数和目标内存对应的输入偏置匹配。如果返回值用于某个分支检查,且未满足分支约束,Angora 会增加输入长度直到满足该分支约束。
实验与性能评价
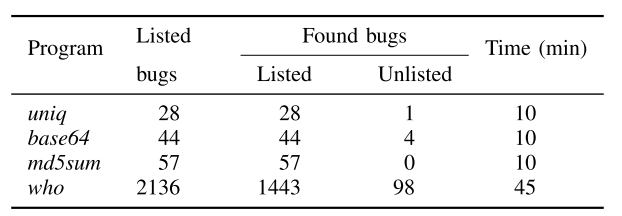
LAVA-M 数据集由 4 个 GNU coreutils 程序组成(uniq, base64, md5sum 和 who),注入了大量的实际 bug,且每个注入的 bug 有一个独特的 ID,在被触发时被打印出来。在 LAVA-M 上,Angora 的测试结果如下图:
- 项目地址:https://github.com/AngoraFuzzer/Angora
- 数据集链接:http://panda.moyix.net/~moyix/lava_corpus.tar.xz
- 实验步骤说明:https://github.com/AngoraFuzzer/Angora/blob/master/docs/lava.md
特点
- 首次引入梯度下降作为模糊测试输入变异的优化方法
- 通过添加类型推断,压缩了输入变异的状态空间
- 通过上下文敏感的分支统计,为模糊测试提供更多的上下文信息
- 使用摊还分析法,证明引入污点跟踪对模糊测试利大于弊