Quick EMUlator(QEMU)
简介
- 仿真器和虚拟化器
- 模式:
- 用户模式仿真:允许一个(Linux)进程执行在不同架构的CPU上,该模式下,QEMU 可以作为进程级虚拟机。
- 系统模式仿真:允许仿真完整的系统,包括处理器和配套的外设,该模式下,QEMU 也可以作为系统虚拟机
- 主要用途
- 跨平台编译与开发环境
- 虚拟化,尤其是外设仿真,作为对 xen 和 kvm 的补充
- 安卓仿真器(作为 SDK 的一部分)
动态二进制翻译
动态转译过程:
- 读取源指令流(二进制)-> gen_intermediate_code()
- 解释为微操作(TCG 微操作)-> tcg_gen_code()
- 编译为目标文件(二进制)
- 动态产生目标指令流
- 功能转译:模仿源处理器完成的功能而非执行过程
- 动态二进制翻译:像一个不含解释器的 JIT 编译器
- 解释器逐一执行指令,使得执行速度因为固定的额外开销显著变慢
- 作为替代,QEMU 用自己需要的方式转换代码
- 翻译基本块 -> 生成主机目标代码
- 在翻译缓存中存储翻译块
- Tiny Code Generator (TCG)
- 将源二进制流转换为微操作
- (固定的)寄存器映射来减少产生的 load/store 指令
- 翻译块:不包含跳转指令,以分支指令为分隔,翻译块被转换为主机指令的一个单一序列,并放入翻译缓存
- 缓存中的翻译块用它们的客户机虚拟地址(如PC值)索引,因此可以快速查得
- 翻译缓存的大小默认为 32MB,但是可以自行配置
- 一旦缓存运行超出空间,全部缓存被清理
- 块链接
- 在主循环中,通过 cpu_exec() 进入下一代码块
- 程序执行至无后续链接的代码块,则通过后置代码返回 cpu_exec()
块链接
- 正常情况下,每个转译块的执行,被特殊代码块的执行环绕
- 前置代码初始化处理器以生成跳转并执行到指定代码块的主机代码
- 后置代码恢复处理器至正常状态并返回到主循环
- 在每个代码块后返回主循环显著增加了额外开销
- 因此在下一个代码块已经翻译好的情况下,QEMU会patch原始块,以跳过后置代码而直接执行下一代码块。
- 在代码块间直接跳转:
- 在存放返回至后置代码的指令和代码块返回间,留出跳转空间
- 每当一个块返回时,尝试链接至下一代码块
- 当链接在数个连续块间完成后,代码块间将形成链和环
- 这允许 QEMU 仿真内循环时,无需运行额外的代码
- 这也意味着,在循环过程中,只有在遇到未链接或未翻译的块需要被执行时,才将控制权还给 QEMU
- 异步中断
- QEMU 不主动检查每个基础块中是否有硬件中断在等待,而是由用户异步的调用特定函数 cpu_interrupt() 来告知 QEMU 中断正在等待
- 该函数的功能是重置当前正在执行的块链,返回至 CPU 仿真器的主循环
- 异步中断常常来自其它线程
寄存器映射
- 当目标架构寄存器个数多于源架构寄存器个数
- 如果目标架构寄存器不够,则采用每个代码块/每个trace/每个循环为单位进行寄存器映射
- 最差情况,放弃映射不常用的源架构寄存器
- 处理 PC 寄存器
- TPC(目标) 和 SPC(源)不同
- 对间接跳转指令,保存 SPC 的寄存器必须提供将 SPC 映射至 TPC 的方式,即仿真器在任何时刻都需要跟踪 SPC
其它主要 QEMU 组件
- 内存地址转译
- 软件控制内存管理单元(模型)来翻译目标虚拟地址为主机虚拟地址:两级客户机物理页描述符表
- 映射客户机虚拟地址和主机虚拟地址:定位翻译缓存(tlb_table),直接将客户机虚拟地址转换为主机虚拟地址
- 映射客户机虚拟地址和寄存器输入输出功能:缓存被使用的内存映射 I/O 访问(iotlb)
- 设备仿真
- i440FX host PCI bridge, Cirrus CLGD 5446 PCI VGA card, PS/2 mouse & keyboard, PCI IDE interfaces (HDD, CDROM), PCI & ISA network adapters, Serial ports, PCI UHCI USB controller & virtual USB hub, …
SoftMMU
- MMU 虚拟->物理地址转换在每个访存操作中都要完成
- 通过地址转换缓存加速转换
- 为了避免每次 MMU 映射改变造成翻译块缓存清空,QEMU 采用物理方式索引转译缓存
- 每个基础块由其物理地址索引
- 当 MMU 映射改变时,仅仅基础块的链需要改变(一个基础块可能不再能直接跳转到下一个)
补充
QEMU 架构
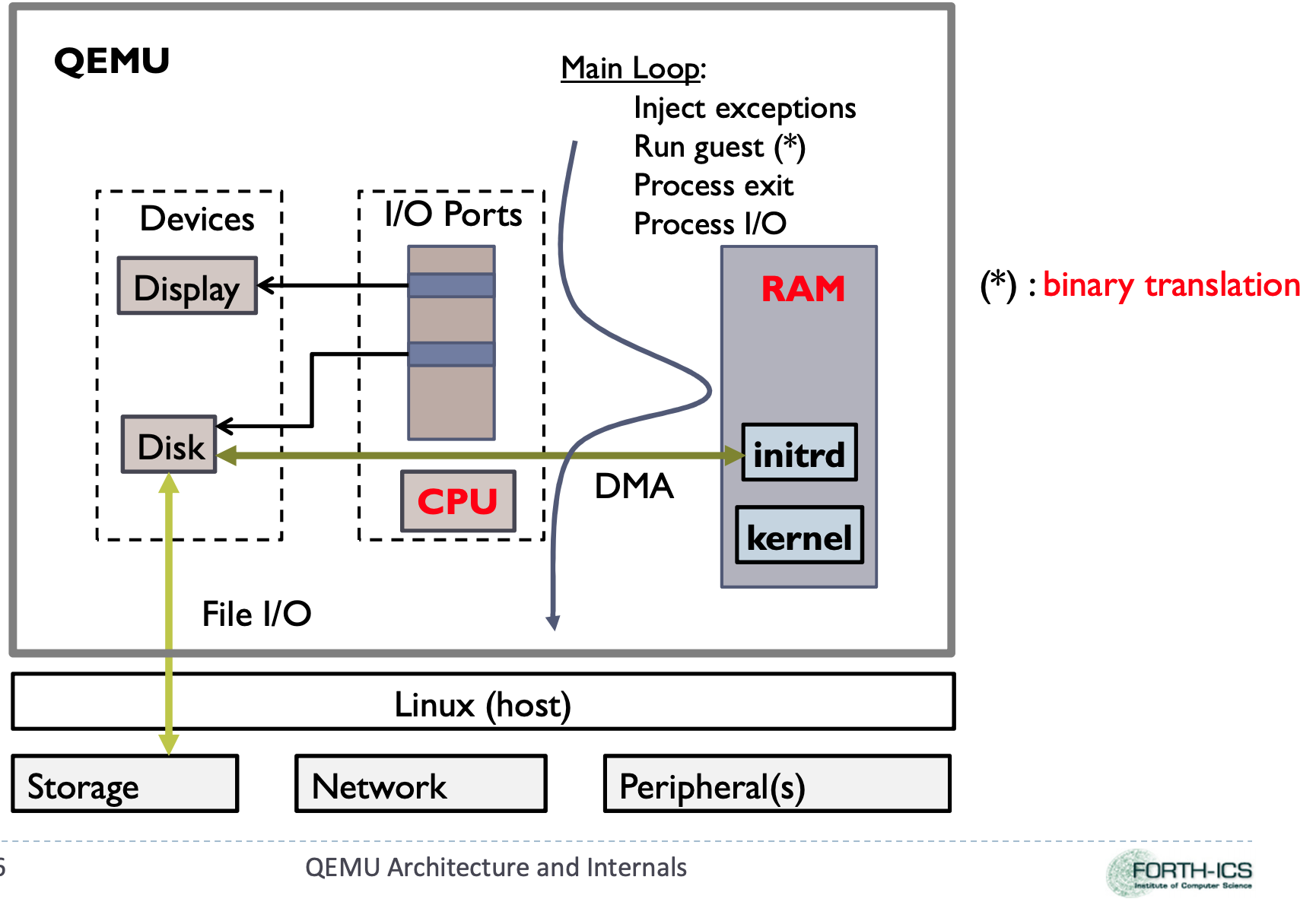
QEMU 存储栈

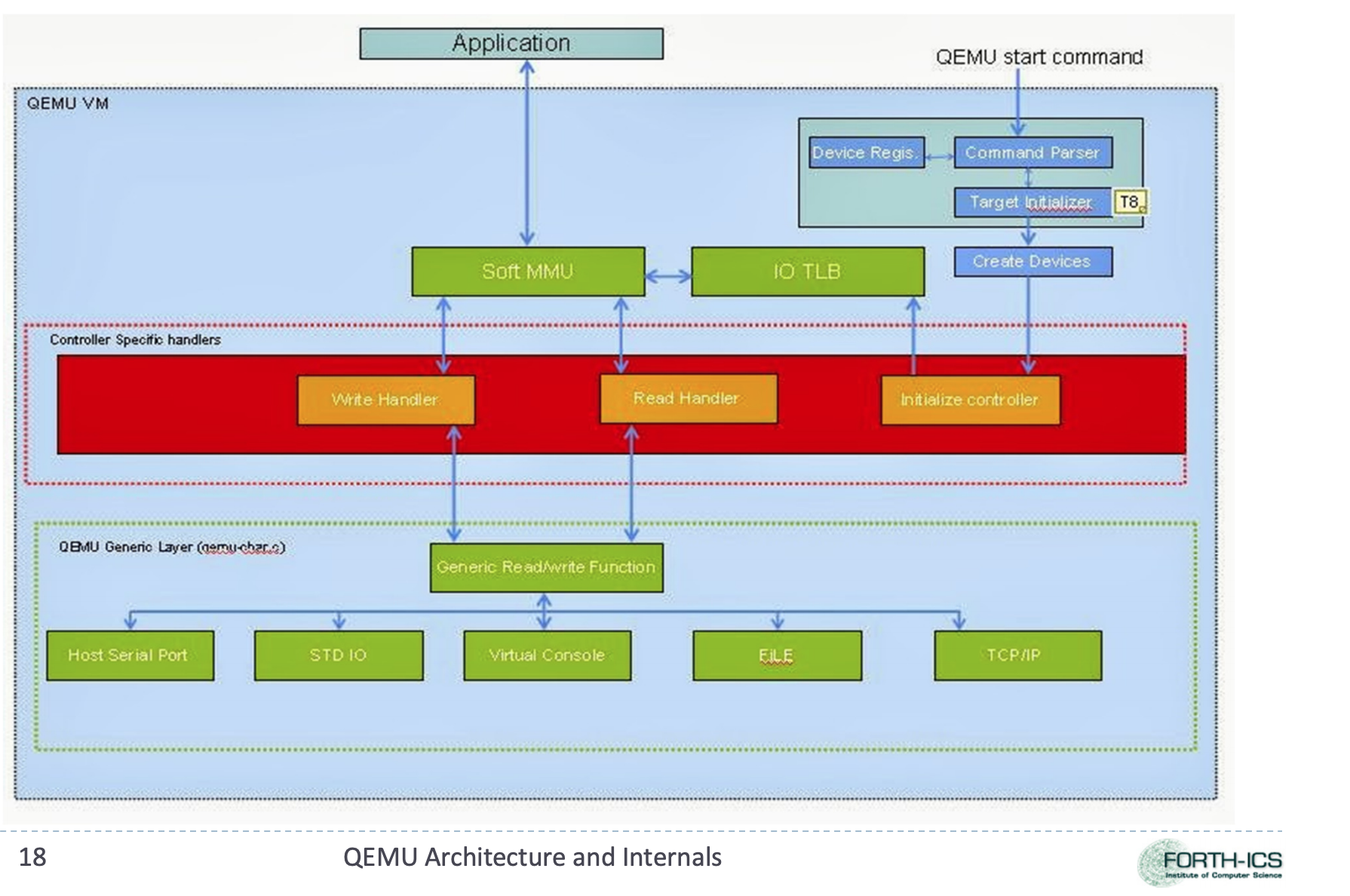
QEMU I/O 控制流
QEMU 与 KVM 交互
QEMU 纯软件虚拟化模拟器,几乎可以模拟任何硬件设备。通常用来模拟一台能够独立运行操作系统的虚拟机.QEMU 模拟硬件将指令转译给真正的硬件。
纯软件实现仿真器性能较低,往往需要 KVM (硬件虚拟化加速)帮助完成高频的 CPU 和内存虚拟化,QEMU 则负责 I/O 虚拟化。
1 | // 第一步,获取到 KVM 句柄 |
QEMU 源码结构
- /vl.c: 最主要的模拟循环,虚拟机环境初始化,和 CPU 的执行。
- /target-arch/translate.c: 将 guest 代码翻译成不同架构的 TCG 操作码。
- /tcg/tcg.c: 主要的 TCG 代码。
- /tcg/arch/tcg-target.c: 将 TCG 代码转化生成主机代码。
- /cpu-exec.c: 主要寻找下一个二进制翻译代码块,如果没有找到就请求得到下一个代码块,并且操作生成的代码块。
| 函数 | 路径 | 注释 |
|---|---|---|
| main_loop | /vl.c | 判断运行状态 |
| qemu_main_loop_start | /cpus.c | 分时运行 CPU 核 |
| struct CPUState | /target-xyz/cpu.h | CPU 状态结构体 |
| cpu_exec | /cpu_exec.c | 主要执行循环 |
| struct TranslationBlock | /exec-all.h | TB(二进制翻译代码块)结构体 |
| cpu_gen_code | translate-all.c | 初始化真正的代码生成 |
| tcg_gen_code | /tcg/tcg.c | tcg 代码翻译成 host 代码 |